Self-Healing and Cost-Effective Architecture for Web Applications on AWS
Question
Your company currently has a set of EC2 Instances running a web application which sits behind an Elastic Load Balancer.
You also have an Amazon RDS instance which is used by the web application.
You have been asked to ensure that this architecture is self healing in nature and cost effective.
Which of the following would fulfill this requirement.
Choose 2 answers from the option given below.
Answers
Explanations
Click on the arrows to vote for the correct answer
A. B. C. D.Answer - A and D.
The following diagram from AWS showcases a self-healing architecture where you have a set of EC2 servers as Web server being launched by an Autoscaling Group.
The AWS Documentation mentions the following.
Amazon RDS Multi-AZ deployments provide enhanced availability and durability for Database (DB) Instances, making them a natural fit for production database workloads.
When you provision a Multi-AZ DB Instance, Amazon RDS automatically creates a primary DB Instance and synchronously replicates the data to a standby instance in a different Availability Zone (AZ)
Each AZ runs on its own physically distinct, independent infrastructure, and is engineered to be highly reliable.
In case of an infrastructure failure, Amazon RDS performs an automatic failover to the standby (or to a read replica in the case of Amazon Aurora), so that you can resume database operations as soon as the failover is complete.
Since the endpoint for your DB Instance remains the same after a failover, your application can resume database operation without the need for manual administrative intervention.
For more information on Multi-AZ RDS, please refer to the below link:
https://aws.amazon.com/rds/details/multi-az/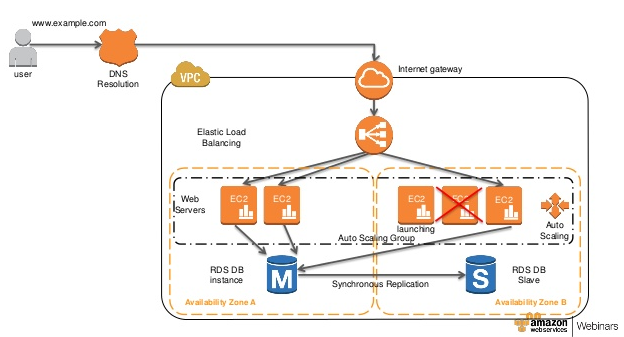
To fulfill the requirement of ensuring that the architecture is self-healing and cost-effective, we need to address two aspects:
- Auto-scaling: Automatically scaling the resources up or down based on the current demand to optimize cost.
- High Availability: Ensuring that the architecture is highly available and can tolerate component failures.
Option A and D fulfill these requirements:
A. Use Cloudwatch metrics to check the utilization of the web layer. Use Autoscaling Group to scale the web instances accordingly based on the cloudwatch metrics.
This option suggests using Amazon CloudWatch metrics to monitor the utilization of the web instances and then using Autoscaling Groups to automatically scale the instances based on the metrics. By doing this, the infrastructure can automatically increase or decrease capacity based on the demand, ensuring that the application is always available to users while optimizing the cost.
This approach can help address the self-healing and cost-effective requirements of the infrastructure. CloudWatch metrics can be used to detect increases or decreases in traffic, and the Autoscaling Groups can automatically launch or terminate instances in response to the changes. This approach ensures that the infrastructure is always right-sized to meet the current demand while also minimizing cost.
D. Utilize the Multi-AZ feature for the Amazon RDS layer.
This option suggests using the Multi-AZ feature of Amazon RDS to improve the availability of the database layer. Multi-AZ automatically replicates data to a standby instance in a different Availability Zone (AZ), providing data redundancy and failover capabilities. This ensures that the database is always available, even in the event of a failure.
By using Multi-AZ, the architecture can be made highly available and resilient to component failures. If the primary database instance fails, Amazon RDS automatically switches to the standby instance, minimizing the downtime and ensuring that the web application can continue to function without any disruption.
In conclusion, by implementing option A and D, the architecture can be made self-healing and cost-effective while ensuring high availability and resilience to component failures.