Auto Scaling Group and ELB Health Check Troubleshooting
Question
You have an Auto Scaling group associated with an Elastic Load Balancer (ELB)
You have noticed that instances launched via the Auto Scaling group are being marked unhealthy due to an ELB health check, but these unhealthy instances are not terminated.
What do you need to do to ensure that the instances marked unhealthy by the ELB will be terminated and replaced?
Answers
Explanations
Click on the arrows to vote for the correct answer
A. B. C. D.Answer - B.
To discover the availability of your EC2 instances, an ELB periodically sends pings, attempts connections, or sends requests to test the EC2 instances.
These tests are called health checks.
The status of the instances that are healthy at the time of the health check is InService.
The status of any instances that are unhealthy at the time of the health check is OutOfService.
When you allow the Auto Scaling group (ASG) to receive the traffic from the ELB, it gets notified when the instance becomes unhealthy, and then it terminates it.
See the images in the "More information..." section for more details.
Option A is incorrect because changing the threshold will not enable ASG to know about the unhealthy instances.
Option B is CORRECT because when you associate the ELB with ASG, you allow the ASG to receive the traffic from that ELB.
When the health check type is ELB, the ASG will get aware of the unhealthy instances and terminate them.
Option C is incorrect because increasing the interval will still not communicate the information about the unhealthy instances to the ASG.Option D is incorrect because this setting will not communicate the information about the unhealthy instances to the ASG either.
More information on ELB with Auto Scaling Group:
For more information on ELB, please visit the below URL-
https://docs.aws.amazon.com/autoscaling/ec2/userguide/autoscaling-load-balancer.html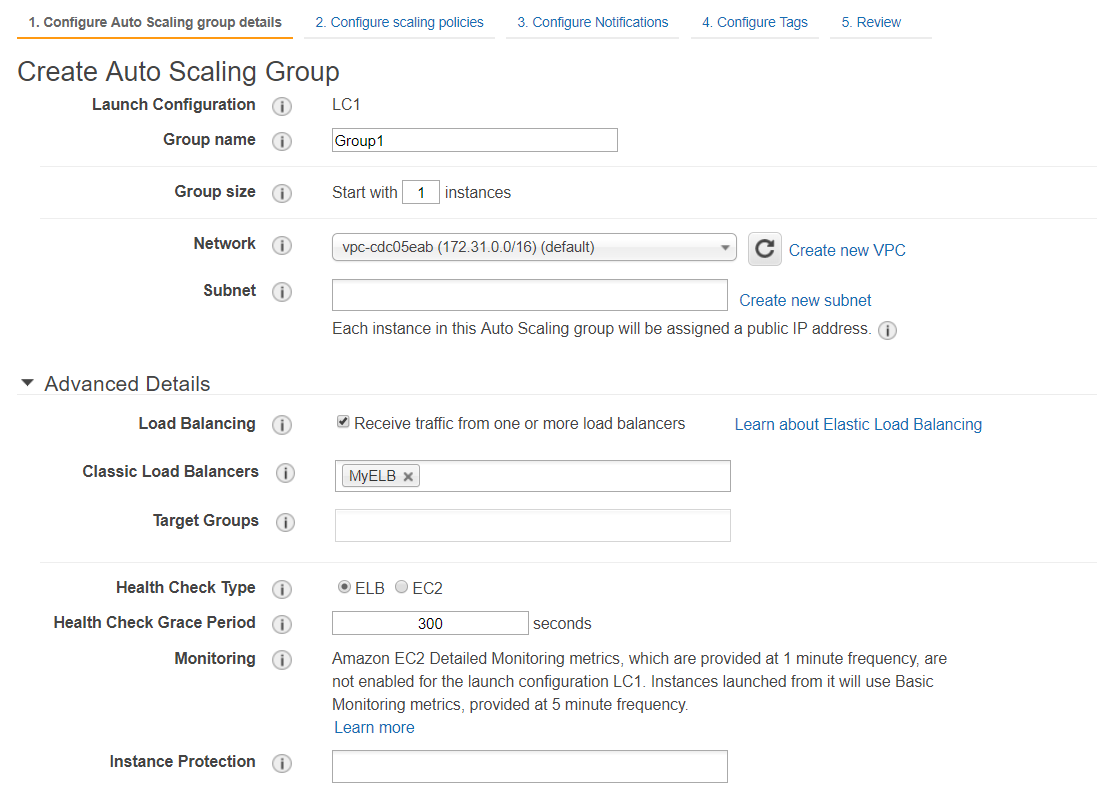
When an Auto Scaling group is associated with an Elastic Load Balancer (ELB), the ELB regularly performs health checks on the instances in the Auto Scaling group to ensure that they are healthy and able to handle incoming traffic. If an instance is found to be unhealthy, the ELB marks it as such, and may optionally remove it from the pool of instances that it sends traffic to.
In this scenario, the issue is that instances marked as unhealthy by the ELB are not being terminated and replaced. This could be due to a number of factors, including the thresholds set on the Auto Scaling group health check, the type of health check being used, or the interval at which the ELB performs health checks.
To ensure that unhealthy instances are terminated and replaced as soon as possible, we need to identify and address the root cause of the issue. Here are the possible options:
A. Change the thresholds set on the Auto Scaling group health check. By default, an Auto Scaling group uses the EC2 instance status checks to determine the health of instances. These checks monitor the underlying health of the instance, such as whether it has network connectivity, and can detect issues such as a crashed operating system. You can also configure the Auto Scaling group to use a custom health check that you define. By changing the thresholds set on the health check, you can adjust the criteria that are used to determine whether an instance is healthy or not. For example, you could increase the timeout for the health check, or adjust the number of consecutive successful checks required before an instance is marked as healthy. However, this option alone may not solve the problem of unhealthy instances not being terminated.
B. Change the type of the health check to "Elastic Load Balancing" in your Auto Scaling group. By default, an Auto Scaling group uses the EC2 instance status checks to determine the health of instances, but you can also configure it to use a health check based on the Elastic Load Balancer. When you select this option, the Auto Scaling group relies on the health status reported by the ELB, rather than performing its own health checks. This means that instances will be terminated and replaced as soon as the ELB marks them as unhealthy. This is likely the best option to solve the problem of unhealthy instances not being terminated.
C. Increase the value for the Health check interval set on the Elastic Load Balancer. The health check interval determines how frequently the ELB checks the health of instances. By increasing the value of the health check interval, you can reduce the load on the ELB and potentially reduce the number of false positives (i.e., instances that are marked as unhealthy but are actually healthy). However, this option may not address the root cause of the issue, which is why unhealthy instances are not being terminated.
D. Change the health check on the Elastic Load Balancer to use TCP rather than HTTP checks. By default, the ELB uses HTTP checks to determine the health of instances. However, if instances are behind a firewall or have a non-standard HTTP configuration, they may fail the health check even if they are otherwise healthy. By changing the health check to use TCP checks, the ELB simply checks whether it can establish a connection to the instance's IP address and port, without checking the contents of the response. This can reduce the likelihood of false positives, but may not solve the problem of unhealthy instances not being terminated.
In summary, option B (Change the type of the health check to "Elastic Load Balancing" in your Auto Scaling group) is likely the best option to ensure that unhealthy instances are terminated and replaced as soon as possible. However, you may want to consider other options as well, depending on the specific circumstances of your deployment.
