Source and Destination Locations in AWS Data Pipeline Service
Question
You're planning on using the data pipeline service to transfer data from Amazon S3 to Redshift.
You need to define the source and destination locations.
Which of the following part of the data pipeline service allows you to define these locations?
Answers
Explanations
Click on the arrows to vote for the correct answer
A. B. C. D.Answer - A.
This is given in the AWS Documentation.
Option B is incorrect since the Task Runner is an application that polls AWS Data Pipeline for tasks and then performs those tasks.
Option C is incorrect since an activity is a pipeline component that defines the work to perform.
Option D is incorrect since a resource is the computational resource that performs the work that a pipeline activity specifies.
For more information on Data Nodes, please refer to the below URL-
https://docs.aws.amazon.com/datapipeline/latest/DeveloperGuide/dp-concepts-datanodes.html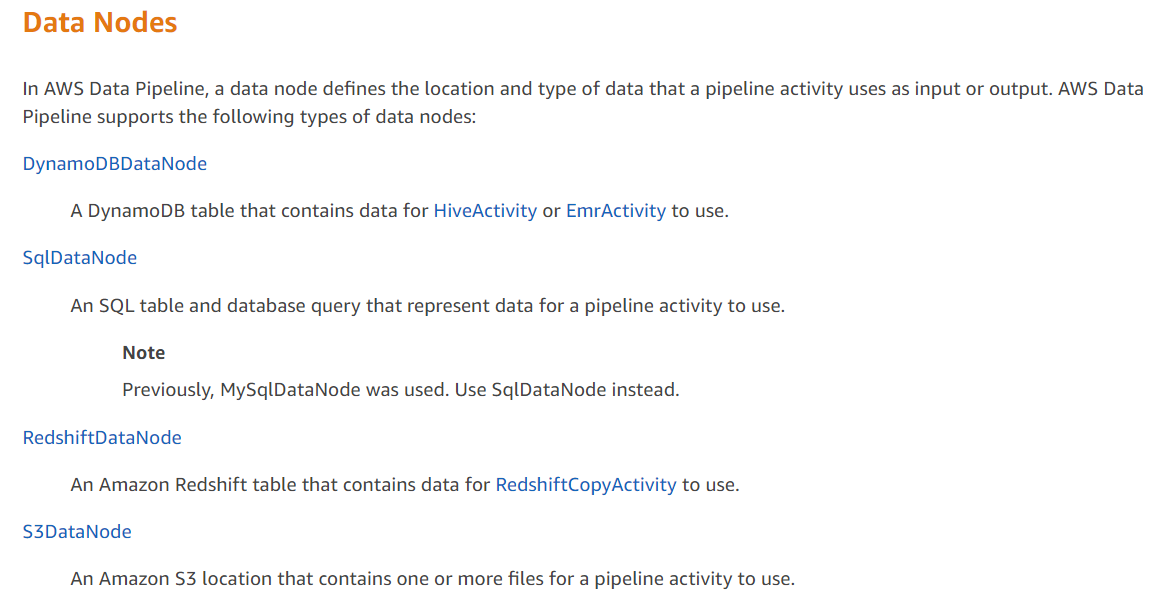
The correct answer is D. Resources.
AWS Data Pipeline is a web service that allows you to automate the movement and transformation of data within AWS services. It is used to move data from one location to another and perform data processing activities such as running SQL queries, executing scripts, and performing data validations.
To create a data pipeline, you must define the source and destination locations, as well as any intermediate processing steps. These components are known as pipeline resources.
Pipeline resources include the following:
- Data nodes: Represent data sources such as Amazon S3 buckets or DynamoDB tables.
- Activities: Represent processing steps such as running SQL queries, executing scripts, or performing data validations.
- Task runner: A software application that is installed on an Amazon EC2 instance, which runs the pipeline activities.
- Resources: Represent the data pipeline itself, and include information about the scheduling, dependencies, and pipeline objects such as the data nodes and activities.
In this scenario, the source location is Amazon S3 and the destination location is Redshift. Therefore, you would use the Resources component of the AWS Data Pipeline service to define these locations. You would create a data node for the Amazon S3 bucket, and an activity for loading the data into Redshift. You would also define the scheduling and dependencies for the pipeline.
