Efficient Architecture for Real-time User Behavior Prediction and Ad Hoc Queries
Question
You are building a machine learning model for your user behavior prediction problem using your company's user interaction data stored in DynamoDB.
You want to get your data into CSV format and load it into an S3 bucket so you can use it for your machine learning algorithm to give personalized recommendations to your users.
Your data set needs to be updated automatically to produce real-time recommendations.
Your business analysts also want to have the ability to run ad hoc queries on your data. Which of the following architectures will be the most efficient way to achieve this?
Answers
Explanations
Click on the arrows to vote for the correct answer
A. B. C. D.Answer: A.
Option A is correct.
AWS Data Pipeline is used here to schedule frequent runs of the described workflow: DynamoDB export, transformation, and running the model to give real-time predictions.
Option B is incorrect.
This approach lacks the pipeline coordination described in.
Option A.Option C is incorrect.
AWS DMS does not support DynamoDB as a data source.
Also, this approach lacks the pipeline coordination described in.
Option A.Option D is incorrect.
You would have to write more code to make this option work when compared to option A.
You would need to write an extraction job to make the DynamoDB data into a Kinesis producer.
You would also have to write the consumer ETL job.
Also, this approach lacks the pipeline coordination described in.
Option A.Reference:
Please see the AWS Data Pipeline developer guide titled What is AWS Data Pipeline, and AWS Database Migration Service user guide titled How AWS Data Migration Service Works specifically the section on sources, the Amazon Kinesis Data Streams developer guide titled Amazon Kinesis Data Streams Terminology and Concepts.
Here is a diagram of the best option:
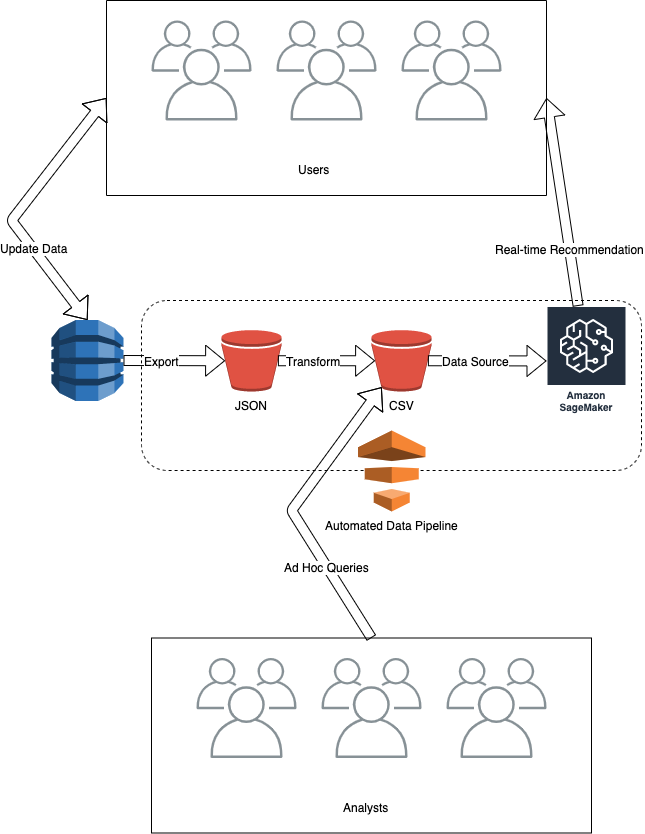
The most efficient architecture to achieve the goal of real-time recommendations from DynamoDB data stored in CSV format in an S3 bucket, with the ability to perform ad hoc queries, is option A: Use AWS Data Pipeline to coordinate the following set of tasks: export DynamoDB data to S3 as JSON; Convert JSON to CSV; SageMaker model uses the data to produce real-time predictions; analysts use Amazon Athena to perform ad hoc queries against the CSV data in S3.
Here is a detailed explanation of why option A is the most efficient architecture:
Exporting DynamoDB data to S3 as JSON:
- AWS Data Pipeline allows exporting data from DynamoDB to S3 in JSON format.
- Exporting data in JSON format enables the subsequent step of converting the data to CSV format.
Converting JSON to CSV:
- AWS Data Pipeline provides built-in support to transform data in JSON format to CSV format.
- By converting data to CSV format, it can be used as input to machine learning algorithms and data analysts can perform ad hoc queries using Amazon Athena.
SageMaker model uses the data to produce real-time predictions:
- SageMaker is a managed machine learning service that provides pre-built algorithms and tools to build, train, and deploy machine learning models at scale.
- The converted CSV data in the S3 bucket can be used as input to a SageMaker model to produce real-time predictions.
Analysts use Amazon Athena to perform ad hoc queries against the CSV data in S3:
- Amazon Athena is an interactive query service that makes it easy to analyze data in S3 using standard SQL.
- The converted CSV data stored in the S3 bucket can be easily queried using Amazon Athena by analysts to perform ad hoc queries.
In summary, the option A architecture provides a simple and efficient way to extract data from DynamoDB, transform it into CSV format, use it as input for a machine learning model to produce real-time recommendations, and allow analysts to perform ad hoc queries using Amazon Athena.
