Self-Healing Architecture for AWS Web Application
Question
Your company currently has a set of EC2 Instances running a web application that sits behind an Elastic Load Balancer.
You also have an Amazon RDS instance which is accessible from the web application.
You have been asked to ensure that this architecture is self-healing in nature.
What would fulfill this requirement? (SELECT TWO)
Answers
Explanations
Click on the arrows to vote for the correct answer
A. B. C. D.Correct Answers - A and D.
The following diagram from AWS showcases a self-healing architecture where you have a set of EC2 servers as a Web server launched by an Auto Scaling Group.
AWS Documentation mentions the following.
Amazon RDS Multi-AZ deployments provide enhanced availability and durability for Database (DB) Instances, making them a natural fit for production database workloads.
When you provision a Multi-AZ DB Instance, Amazon RDS automatically creates a primary DB Instance and synchronously replicates it to a standby instance in a different Availability Zone (AZ)
Each AZ runs on its own physically distinct, independent infrastructure and is engineered to be highly reliable.
In case of an infrastructure failure, Amazon RDS performs an automatic failover to the standby (or to a read replica in the case of Amazon Aurora) so that you can resume database operations as soon as the failover is complete.
Since the endpoint for your DB Instance remains the same after a failover, your application can resume database operation without the need for manual administrative intervention.
For more information on Multi-AZ RDS, please refer to the below link-
https://aws.amazon.com/rds/details/multi-az/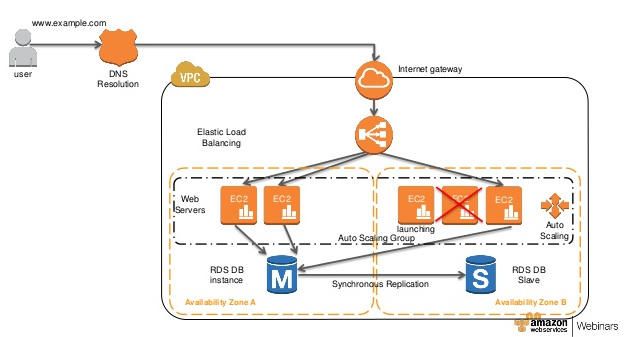
To ensure self-healing architecture, we need to detect failures and automatically recover them without human intervention. In the given scenario, we can achieve this by utilizing the following two options:
Option A: Use CloudWatch metrics to check the utilization of the web layer. Use Auto Scaling Group to scale the web instances accordingly based on the CloudWatch metrics.
This option focuses on scaling the web layer automatically based on the traffic load. We can set up CloudWatch metrics to monitor the utilization of the web layer, such as CPU utilization, network traffic, or HTTP 5xx errors. When the metrics cross a certain threshold, we can configure an Auto Scaling Group to automatically launch new EC2 instances to handle the increased traffic. Additionally, we can configure the Auto Scaling Group to terminate instances when the traffic load decreases.
By automatically scaling the web layer, we can ensure that our web application can handle the increased traffic load without downtime. It also ensures that the web application is highly available and fault-tolerant.
Option D: Utilize the Multi-AZ feature for the Amazon RDS layer.
This option focuses on providing fault tolerance and high availability to the RDS layer. Multi-AZ is a feature that automatically replicates the primary RDS instance to a standby instance in a different availability zone (AZ). The standby instance is continuously synchronized with the primary instance, so it can take over in case the primary instance fails.
By utilizing the Multi-AZ feature, we can ensure that our RDS instance is highly available and fault-tolerant. If the primary instance fails, the standby instance can take over within minutes, and our application can continue to function without interruption.
Option B and C are not correct:
Option B: Use CloudWatch metrics to check the utilization of the database servers. Use Auto Scaling Group to scale the database instances accordingly based on the CloudWatch metrics.
Scaling the database layer is not a recommended option since it can cause data consistency issues, and it is not a scalable solution for a large number of users. Therefore, we should not use an Auto Scaling Group to scale the database instances.
Option C: Utilize the Read Replica feature for the Amazon RDS layer.
Read Replicas are used to offload read-only traffic from the primary RDS instance to a replica instance. They are not suitable for self-healing since they do not provide fault tolerance or high availability. Additionally, Read Replicas cannot be used for write operations, so they cannot replace the primary RDS instance in case of failure. Therefore, we should not utilize Read Replica for self-healing.
