Global IT Firm AWS Solutions for Genomics Data Processing
Question
A global IT Firm is working on a project to process Genomics data for a scientific organization.
Researchers are looking for a quick analysis of large amounts of data they need to retrieve from any part of the world seamlessly.
IT Firm has AWS Direct Connect link from on-premise Datacenter to AWS VPC.
As an AWS consultant, they are looking for your guidance to provide a long-term cost-effective solution that can handle any amount of data reliably. Which of the following solutions can be deployed to meet IT firm requirements?
Answers
Explanations
Click on the arrows to vote for the correct answer
A. B. C. D.Correct Answer: A.
Amazon EMR is a big data platform used for processing large amounts of data.
For analyzing large amounts of data, Amazon EMR can be used to provide reliable cost-effective solutions.
It supports open-source tools like Apache Spark, Apache Hive, Apache HBase, Apache Flink, Apache Hudi, and Presto.
Data can be stored in an Amazon S3 bucket to have scalable storage options & can be accessed globally.
With EMR Cluster, compute & storage are decoupled.
For storage, Amazon S3 can be used.
For compute, clusters can be launched as per processing required & stopped when there is no requirement, saving additional cost.
When Apache Spark is deployed on-premise, customers must manage physical infrastructure & large processing requirements.
There is an additional cost of building new infrastructure.
Option B & D are incorrect as deploying Apache Spark at on-premise servers would be a non-scalable solution & will incur additional cost for managing server farms.
Option C is incorrect as storing analytical data in Amazon EC2 instance store would be ideal only for temporary solution & not for long term reliable storage.
For more information on Amazon EMR, refer to the following URLs-
https://docs.aws.amazon.com/emr/latest/ManagementGuide/emr-overview-benefits.html https://aws.amazon.com/emr/?whats-new-cards.sort-by=item.additionalFields.postDateTime&whats-new-cards.sort-order=desc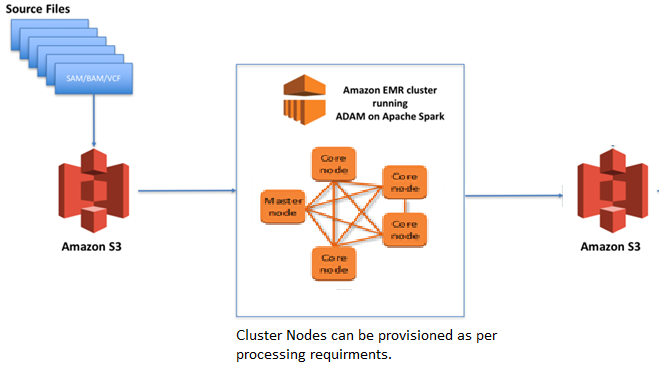
The best solution for this scenario would be A. Use Amazon EMR with Apache Spark & data stored in Amazon S3 bucket.
Explanation: The primary requirement of the project is to process Genomics data quickly and efficiently. The use of AWS Direct Connect link from on-premise Datacenter to AWS VPC suggests that the organization wants to use the cloud infrastructure to handle the processing of the data. Moreover, the requirement for a solution that can handle any amount of data reliably suggests the use of big data processing tools and technologies.
Option A suggests using Amazon EMR (Elastic MapReduce) with Apache Spark for big data processing. Amazon EMR is a managed Hadoop framework that allows for easy deployment and scaling of big data processing jobs. Apache Spark is an open-source distributed computing system that provides a high-level API for big data processing. Amazon EMR also supports other popular big data processing frameworks such as Apache Hadoop, Apache Hive, and Apache Pig.
The data can be stored in an Amazon S3 (Simple Storage Service) bucket, which is a highly scalable and durable object storage service. S3 provides 99.999999999% durability and 99.99% availability for objects stored in it, which ensures the reliability of the data.
Option B suggests using Apache Spark deployed at on-premise servers with data stored in Amazon S3 bucket. This option has some disadvantages as it requires maintaining the on-premise infrastructure, which can be costly and time-consuming. Additionally, it may introduce network latency issues as the data needs to be transferred from on-premise servers to the cloud.
Option C suggests using Amazon EMR with Apache Spark and data stored in Amazon EC2 instance store. The instance store is a temporary storage disk that is physically attached to the Amazon EC2 instance. While the instance store is ideal for temporary data storage, it is not suitable for long-term storage as the data stored in it is lost when the EC2 instance is stopped or terminated. Therefore, it is not a suitable option for this scenario.
Option D suggests using Apache Spark deployed at on-premise servers with data stored in Amazon EC2 instance store. This option has similar disadvantages as option B, including the need to maintain on-premise infrastructure and the risk of network latency issues.
In conclusion, option A is the most suitable solution for this scenario as it leverages the benefits of cloud infrastructure, big data processing frameworks, and highly scalable and durable object storage service.