Automated Recovery for Impaired EC2 Instances
Question
You have an EC2 instance that provides a central file-sharing service to your customers.
You want a mechanism to recover the instance if it becomes impaired automatically.
For example, if there are software issues on the physical host for instance and the system status check fails, you should get a notification and actions should be taken automatically to attempt to recover the instance.
Which method is the best one for you to take?
Answers
Explanations
Click on the arrows to vote for the correct answer
A. B. C. D.Correct Answer - A.
Check the below references for how to automatically recover an EC2 instance:
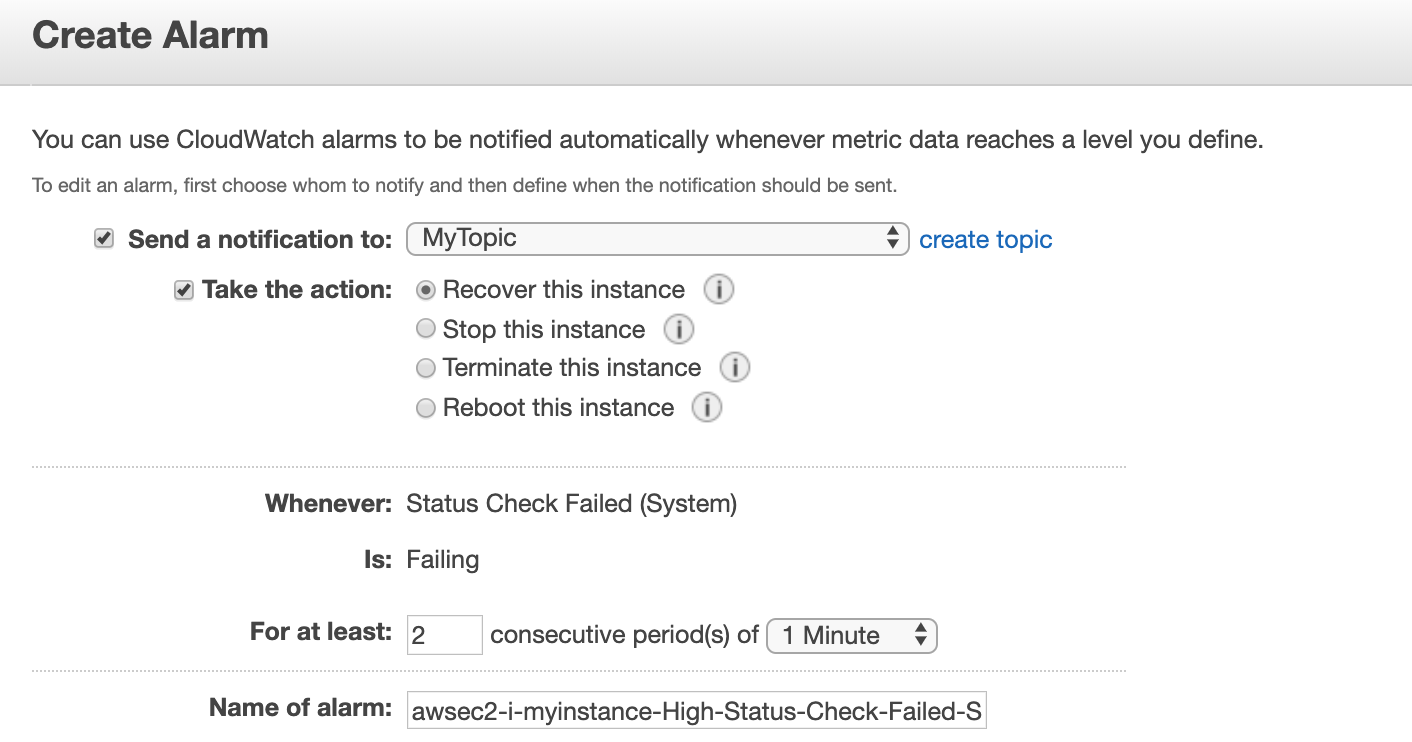
https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/UsingAlarmActions.html#AddingRecoverActions, https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/ec2-instance-recover.html.Option A is CORRECT: Because you can configure a CloudWatch alarm to recover the instance if it fails the status check.
Take the below screenshot as an example:
Option B is incorrect: Because you should not create a new instance since the question asks for recovering the instance.
Option C is incorrect: Because you have to maintain a Lambda function.
This option is not as straightforward as option A.Option D is incorrect: Similar to Option.
B.
What the ASG does is creating a new instance rather than attempting to recover it.
The best method for automatically recovering an EC2 instance that provides a central file-sharing service to customers when it becomes impaired is to configure the instance using an Auto Scaling group and create a CloudWatch alarm to monitor the instance status. If the instance fails the status check, inform the Auto Scaling group to launch a new instance to replace the original one. Therefore, the correct answer is D.
Explanation:
An Auto Scaling group is a group of EC2 instances that are automatically scaled up or down based on user-defined policies. Auto Scaling helps ensure that the desired number of EC2 instances are running to handle the incoming traffic, and it can also help to recover the impaired instances. By configuring the EC2 instance as part of an Auto Scaling group, the instance can be automatically replaced if it becomes impaired or stops functioning.
Creating a CloudWatch alarm to monitor the EC2 instance status is a good practice. The CloudWatch alarm can be set up to check the status of the instance every minute and send an alert if the status check fails. If the instance is impaired or stopped, the Auto Scaling group can be informed to launch a new instance automatically. This process ensures that the file-sharing service remains available and uninterrupted.
Option A, Creating a CloudWatch alarm to monitor the Amazon EC2 instance. When the instance becomes impaired, trigger an SNS notification and automatically recover the instance, is partially correct. While CloudWatch alarms can be created to monitor the instance status and SNS can be used to send notifications, the recovery of the instance needs to be handled separately.
Option B, Adding the instance to an Auto Scaling group so that the ASG can automatically add a new instance when the system status check fails, is also partially correct. Adding the instance to an Auto Scaling group is a good practice to ensure that the instance is replaced automatically if it becomes impaired or stops functioning. However, the instance needs to be monitored to detect the failure, which requires a CloudWatch alarm.
Option C, Creating a CloudWatch Event rule to monitor the EC2 instance state. When the instance is stopped or terminated, trigger an SNS notification and a Lambda function to recover the instance automatically, is not the best solution for this scenario. While it is possible to monitor the instance state and trigger notifications, it does not address the issue of recovering the instance when it becomes impaired. This option is better suited for scenarios where instances are intentionally stopped or terminated and need to be replaced.
In conclusion, option D, configuring the instance using an Auto Scaling group and creating a CloudWatch alarm to monitor the EC2 instance status, is the best method for automatically recovering an EC2 instance that provides a central file-sharing service to customers when it becomes impaired.