AWS Glue Schema Discovery and Crawler
Question
Your organization stores customer data in an Amazon DynamoDB table.
You need to use AWS Glue to create the ETL (extract, transform, and load) jobs to build the data warehouse.
In AWS Glue, you need a component to determine the schema from DynamoDB, and populate the AWS Glue Data Catalog with metadata.
Which of the following components should be used to implement it?
Answers
Explanations
Click on the arrows to vote for the correct answer
A. B. C. D.Correct Answer - C.
You can use a crawler to populate the AWS Glue Data Catalog with tables.
This is the primary method used by most AWS Glue users.
A crawler can crawl multiple data stores in a single run.
Upon completion, the crawler creates or updates one or more tables in your Data Catalog.
The AWS Glue Data Catalog can then be used to guide ETL operations.
Option A is incorrect because the table in AWS Glue is used to define the data schema.
It is not the correct component to perform the ETL jobs.
Option B is incorrect because the table in Athena is not the correct component to populate the AWS Glue Data Catalog.
Option C is CORRECT because, in AWS Glue, you can use a Crawler that connects to the DynamoBD table and populates the Data Catalog.
Option D is incorrect because Classifier is a component in Crawler that generates a schema.
You should use Crawler to perform the ETL jobs instead of Classifier.
The classifier is not a separate component.
Reference:
https://docs.aws.amazon.com/glue/latest/dg/components-overview.html https://aws.amazon.com/blogs/database/simplify-amazon-dynamodb-data-extraction-and-analysis-by-using-aws-glue-and-amazon-athena/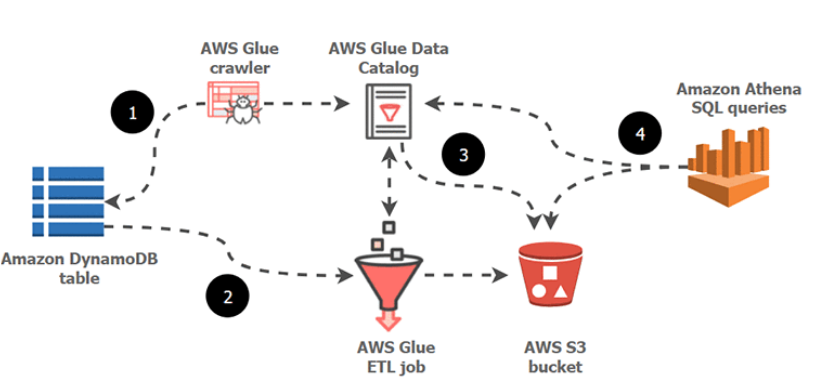
The correct answer is C. Crawler in AWS Glue.
AWS Glue is a fully-managed, serverless data integration service that makes it easy to move data between data stores. AWS Glue ETL jobs allow you to transform data and store it in a variety of data sources.
In this scenario, the organization is using Amazon DynamoDB to store customer data, and AWS Glue to create ETL jobs to build a data warehouse. To populate the AWS Glue Data Catalog with metadata, you need to use a component that can determine the schema from DynamoDB.
AWS Glue Crawler is the component that can automatically discover the schema of the data stored in DynamoDB tables and populate the AWS Glue Data Catalog with metadata. It can infer the schema of your data and create a table definition for you, and it can also automatically update the table definition if the schema changes.
A. Table in AWS Glue is not the correct answer because it is used to define tables manually and not to infer the schema from DynamoDB.
B. Table in Amazon Athena is also not the correct answer because it is used to query data stored in Amazon S3 or other data sources, and not to populate the AWS Glue Data Catalog with metadata from DynamoDB.
D. Classifier in AWS Glue is used to classify the data based on its format and schema, but it cannot infer the schema from DynamoDB.
