Increase Performance for Web Page Analysis
Question
While analyzing billions of web pages in a company, you have noticed some munging processes are exceeding SLAs even after using X1e instances suitable for HPC applications.
After monitoring logs, trailing, and tracing data closely, you noticed that write operations involving S3 content pre-processing causing 80% of the bottleneck.
In comparison, read operations for post-processing and LIST operations are together leading to the remaining 20% of congestion.
Which two options are recommended to increase performance in this scenario? (Select TWO)
Answers
Explanations
Click on the arrows to vote for the correct answer
A. B. C. D. E.Answers: B and D.
The problem description highlights write operations having 80% of the impact when compared to read operations.
Amazon S3 Transfer Acceleration helps especially in this scenario along with multipart upload.
X1 and X1e instances are memory-optimized instances designed for running large-scale and in-memory applications in the AWS Cloud.
Generally, it is a recommended practice to benefit from byte-range fetches and appropriate distributing key names.
Another complex practice to avoid expensive LIST operations relies on a search framework to keep track of all objects in an S3 bucket.
Lambda triggers are used to populate DynamoDB tables with object names and metadata when those objects are put into Amazon S3 then OpenSearch Service is used to search for specific assets, related metadata, and data classifications.
Option A is incorrect because this option is not applicable as you would need to migrate the data to a relational database in RDS.
Option C is incorrect because the phrase does not make sense, especially considering that the Amazon S3 service is exactly the opposite of a single network endpoint.
Option E is incorrect because you cannot migrate an existing S3 bucket into another AWS Region, rather create a new S3 bucket in the region and copy the data to it.
However, the statement does not solve the problem description.
References:
https://aws.amazon.com/s3/transfer-acceleration/ https://docs.aws.amazon.com/whitepapers/latest/s3-optimizing-performance-best-practices/use-byte-range-fetches.html https://docs.aws.amazon.com/whitepapers/latest/building-data-lakes/data-cataloging.html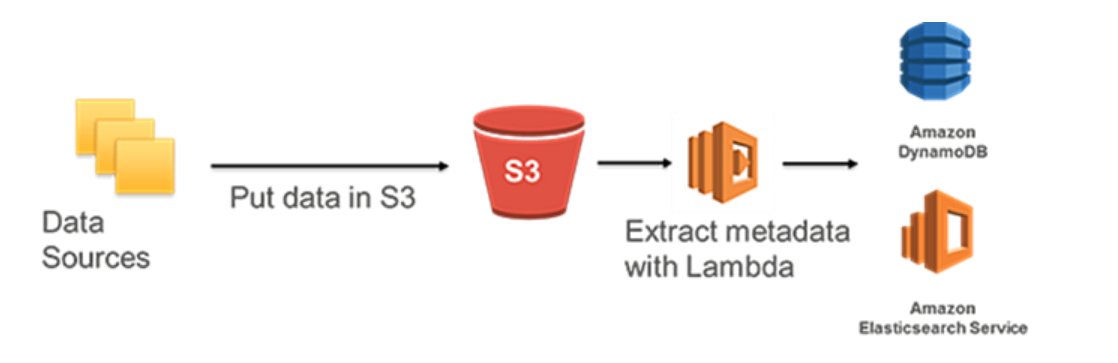
The scenario described in this question involves analyzing billions of web pages in a company, and the munging processes are exceeding SLAs even after using X1e instances suitable for HPC applications. Upon further analysis, it was found that the write operations involving S3 content pre-processing are causing 80% of the bottleneck, and the remaining 20% of congestion is caused by read operations for post-processing and LIST operations.
To increase performance in this scenario, the two recommended options are:
Option B: Using Amazon S3 Transfer Acceleration, Multipart upload, parallelized reading via byte-range fetches, and partitioned prefix for distributing key names as part of naming patterns.
Amazon S3 Transfer Acceleration is a feature that enables faster transfer of files over long distances between the client and an S3 bucket. It utilizes Amazon CloudFront's globally distributed edge locations to accelerate the transfer of files over the internet. By using this feature, you can accelerate both upload and download speeds, which will help to reduce the overall processing time.
Multipart upload allows you to upload large files in parts and upload them concurrently, thereby increasing the speed of uploads. This is especially useful when you are dealing with very large files, and the network bandwidth is a bottleneck.
Parallelized reading via byte-range fetches involves requesting multiple parts of a file simultaneously, thereby improving the speed of downloads. This technique is useful when you are dealing with large files that need to be processed quickly.
Partitioned prefix for distributing key names as part of naming patterns involves creating a naming convention for S3 objects that distributes the keys across multiple prefixes, which helps to distribute the load across multiple instances of the application. This technique is useful when you have a large number of objects in an S3 bucket, and you want to improve the performance of read operations.
Option D: Instead of LIST operations, you can build a search catalog to keep track of S3 metadata by using other AWS services like Amazon DynamoDB or Amazon OpenSearch Service.
LIST operations can be slow and resource-intensive, especially when you have a large number of objects in an S3 bucket. Instead of using LIST operations, you can build a search catalog to keep track of S3 metadata by using other AWS services like Amazon DynamoDB or Amazon OpenSearch Service. These services can help you to search and retrieve S3 metadata quickly and efficiently, without having to perform a full LIST operation. This technique is useful when you have a large number of objects in an S3 bucket and want to improve the performance of read operations.
Options A, C, and E are incorrect:
Option A: Migrate S3 files to an RDS database with write-optimized IOPS.
Migrating S3 files to an RDS database with write-optimized IOPS is not a recommended solution in this scenario. RDS is a database service, and it is not designed to handle unstructured data like S3 objects. Additionally, RDS may not be able to handle the volume of data involved in this scenario. This technique is not useful when you are dealing with unstructured data like web pages.
Option C: Instead of LIST operations, you can scale storage connections horizontally since Amazon S3 is a very large distributed system similar to a decoupled parallel, single network endpoint. You can achieve the best performance by issuing multiple concurrent requests to Amazon S3.
Scaling storage connections horizontally by issuing multiple concurrent requests to Amazon S3 is not a recommended solution in this scenario. While it is true that Amazon S3 is a large distributed system, issuing multiple concurrent requests may not be an efficient way to handle a large number of objects in an S3 bucket. Additionally, this technique may not help to address the bottleneck caused by write operations involving S3 content pre-processing.
Option E: Combining Amazon S3 and Amazon
