Extracting and Transforming Data in AWS for Big Data Analysis
Question
You are an AWS solutions architect in an IT company.
Your company has a big data product that analyzes data from various sources like transactions, web servers, surveys, and social media.
You need to design a new solution in AWS that can extract data from the source in S3 and transform the data to match the target schema automatically.
Moreover, the transformed data can be analyzed using standard SQL.
Which combination of solutions would meet these requirements in the best way? (Select TWO.)
Answers
Explanations
Click on the arrows to vote for the correct answer
A. B. C. D. E.Correct Answer - C, E.
AWS Glue is a fully managed extract, transform, and load (ETL) service that makes it easy for customers to prepare and load their data for analytics.
AWS Athena is out-of-the-box integrated with AWS Glue Data Catalog, allowing you to create a metadata repository across various services.
AWS Glue and AWS Athena, when used together, can meet the requirements for this case.
Option A is incorrect:Although the ECS cluster may work, it is not fully managed by AWS.
By AWS Glue, you can create and run an ETL job with a few clicks in the AWS Management Console.
Option B is incorrect: Similar reason as.
Option A.
AWS Glue should be considered as the first choice when an extract, transform, and load (ETL) service is required in AWS.
Option C is correct because AWS Glue generates Scala or PySpark (the Python API for Apache Spark) scripts with AWS Glue extensions.
You can use and modify these scripts to perform various ETL operations.
You can extract, clean, and transform raw data, and then store the result in a different repository, where it can be queried and analyzed.
Option D is incorrect: Because AWS QuickSight is a service to deliver insights rather than perform SQL queries.
Option E is CORRECT: Because AWS Athena can directly query the data in AWS Glue Data Catalog with SQL commands.
No additional step is needed.
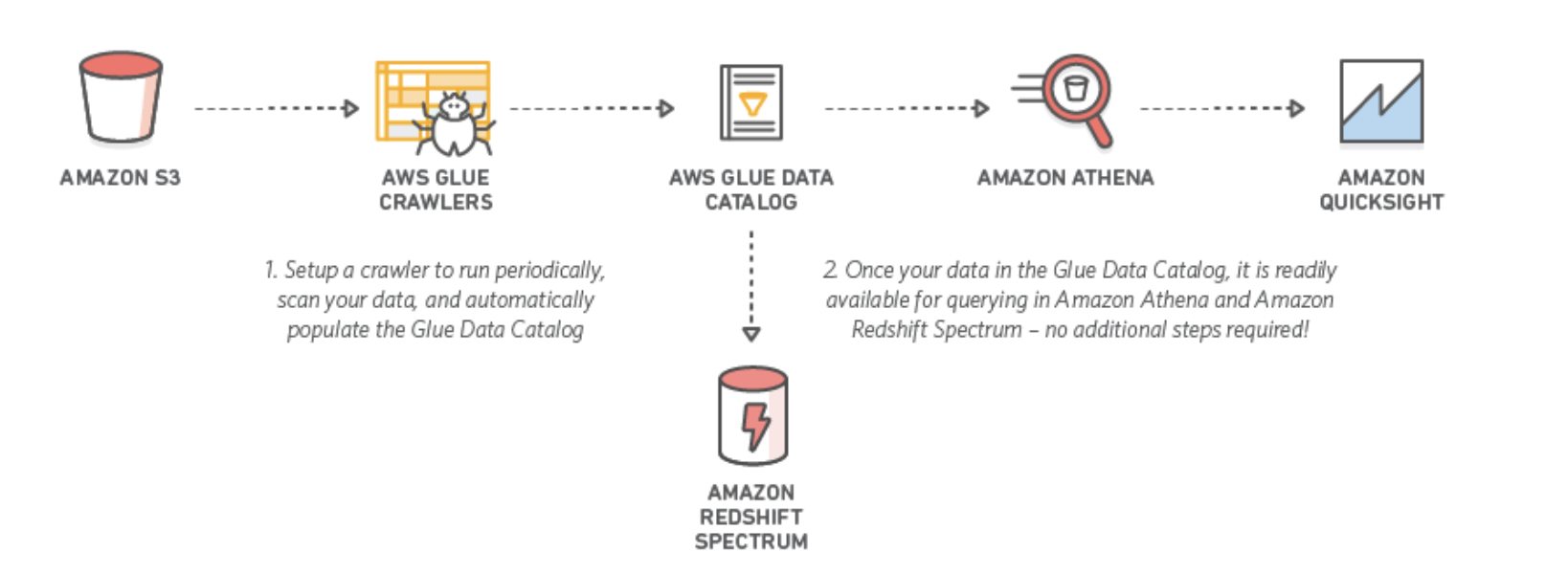
To meet the requirements of extracting and transforming data from various sources to S3 and enabling analysis using standard SQL, the best solution would be a combination of AWS Glue and Athena.
AWS Glue is a fully managed ETL service that makes it easy to move data between data stores. It automatically discovers and profiles your data via a Glue data catalog, and then creates ETL scripts to transform your data from the source schema to the target schema. This makes it easy to build and maintain ETL pipelines, reducing the amount of manual work required to transform data.
Using AWS Glue, you can create a job that extracts the data from S3, transforms it according to the target schema, and loads it back into S3. You can schedule the job to run at a specific time, or trigger it based on events, such as when new data is added to the source.
Once the data is transformed, you can use AWS Athena to query the data using standard SQL commands. Athena is a serverless, interactive query service that makes it easy to analyze data in S3 using SQL. It is highly scalable and can handle large datasets, making it a good fit for big data workloads.
Option A is not the best choice because AWS ECS is a container management service and is not specifically designed for ETL workloads. While it is possible to run ETL jobs on ECS, it requires more setup and management than using a dedicated ETL service like AWS Glue.
Option B is not the best choice because while AWS EMR is a good choice for processing big data workloads, it is not as well-suited for ETL workloads as AWS Glue. EMR requires more setup and management than Glue and is better suited for complex data processing tasks that require distributed computing.
Option D is not the best choice because AWS QuickSight is a business intelligence service that enables visualization and reporting of data, but it is not designed for data transformation or ETL workloads.
Therefore, options C and E are not the best choice either, as Glue and Athena would provide a more cost-effective and streamlined approach to transforming and analyzing data.
