Consolidating and Analyzing Real-Time Logs
Question
Your customer is willing to consolidate their log streams, access logs, application logs, security logs, etc.
in one single system.
Once consolidated, the customer wants to analyze these logs in real-time based on heuristics.
From time to time, the customer needs to validate heuristics, which requires going back to data samples extracted from the last 12 hours? What is the best approach to meet your customer's requirements?
Answers
Explanations
Click on the arrows to vote for the correct answer
A. B. C. D.Answer - B.
Whenever the scenario - just like this one - wants to do real-time processing of a stream of data, always think about Amazon Kinesis.
Also, remember that the records of the stream are available for 24 hours.
Option A is incorrect because SQS is not used for real-time processing of the stream of data.
Option B is CORRECT because Amazon Kinesis is best suited for applying the real-time processing of the stream of data.
Also, the records of the stream are available for 24 hours in Kinesis.
Option C is incorrect because CloudTrail is not used to process the real-time data processing, and EMR is used for batch-processing.
Option D is incorrect because setting autoscaling of EC2 instances is not cost-effective, and EMR is used for batch-processing.
More information on Amazon Kinesis:
Amazon Kinesis is a platform for streaming data on AWS, making it easy to load and analyze streaming data and provide the ability to build custom streaming data applications for specialized needs.
Use Amazon Kinesis Streams to collect and process large streams of data records in real-time.
Use Amazon Kinesis Firehose to deliver real-time streaming data to destinations such as Amazon S3 and Amazon Redshift.
Use Amazon Kinesis Analytics to process and analyze streaming data with standard SQL.
For more information on Kinesis, please visit the below URL-
https://aws.amazon.com/documentation/kinesis/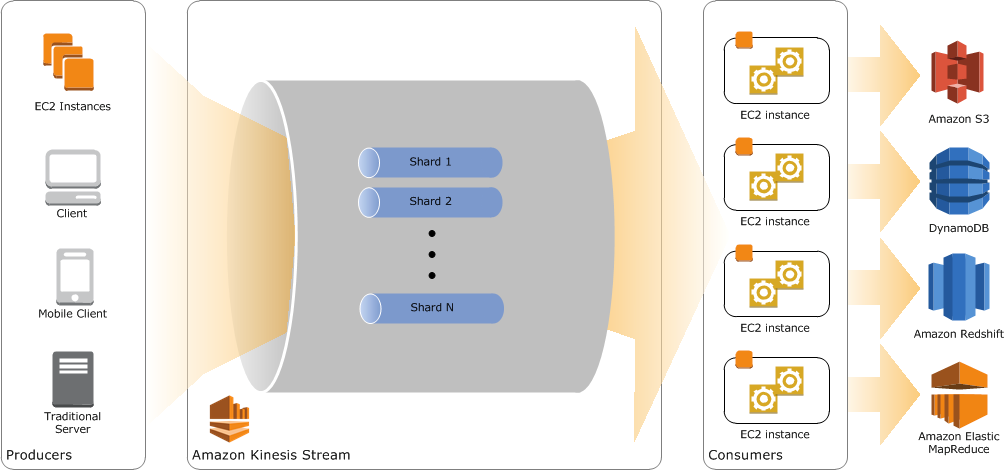
The best approach to meet the customer's requirements is option B, which is to send all the log events to Amazon Kinesis and develop a client process to apply heuristics to the logs.
Amazon Kinesis is a fully managed service that can handle large volumes of streaming data in real-time. It can receive and process data continuously from various sources, such as log files, IoT devices, social media feeds, and more. Kinesis can also store the data for up to 7 days and provide real-time analytics for the incoming data streams.
Sending all the log events to Amazon Kinesis will allow the customer to consolidate their log streams into one single system. The Kinesis client process can apply heuristics to the logs in real-time, allowing for immediate analysis and detection of any issues or anomalies. Kinesis can also scale automatically based on the incoming data volume, ensuring that the customer can handle any spikes in data traffic.
In addition, Kinesis can be used to store the logs for up to 7 days, which can be accessed for further analysis or validation of heuristics. This meets the customer's requirement of going back to data samples extracted from the last 12 hours, as they can retrieve the necessary logs from Kinesis.
Option A, sending all the log events to Amazon SQS and setting up an Auto Scaling group of EC2 servers to consume the logs and apply the heuristics, is not the best approach because SQS is a message queuing service, and is not designed for real-time processing of streaming data. Using EC2 servers to consume the logs can also be inefficient and costly.
Option C, configuring Amazon Cloud Trail to receive custom logs and using EMR to apply heuristics to the logs, is not the best approach because Cloud Trail is primarily used for auditing and monitoring API calls made in AWS, and not for collecting and processing application logs or other types of logs.
Option D, setting up an Auto Scaling group of EC2 Syslog servers and storing the logs in S3, and using EMR to apply heuristics on the logs, is not the best approach because it requires managing and scaling the EC2 servers manually, which can be time-consuming and costly. In addition, S3 is not designed for real-time processing of streaming data, and EMR may not be the best tool for real-time analysis of logs.