Choose the Perfect Data Store for Your Application | AWS Certified Developer - Associate Exam
Question
Your application has the requirement to store data in a backend data store.
Indexing should be possible on the data, but the data does not conform to any schema.
Which of the following would be the ideal data store to choose for this application?
Answers
Explanations
Click on the arrows to vote for the correct answer
A. B. C. D.Answer - B.
The below AWS Documentation mentions the differences between AWS DynamoDB and other traditional database systems.
One of the major differences is the schemaless nature of the database.
Option A is invalid since this is normally used for databases that perform to a particular schema.
Option C is invalid since this is normally used for columnar based databases.
Option D is invalid since this is normally used for object-level storage.
For more information on the differences, please refer to the below link-
https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/SQLtoNoSQL.html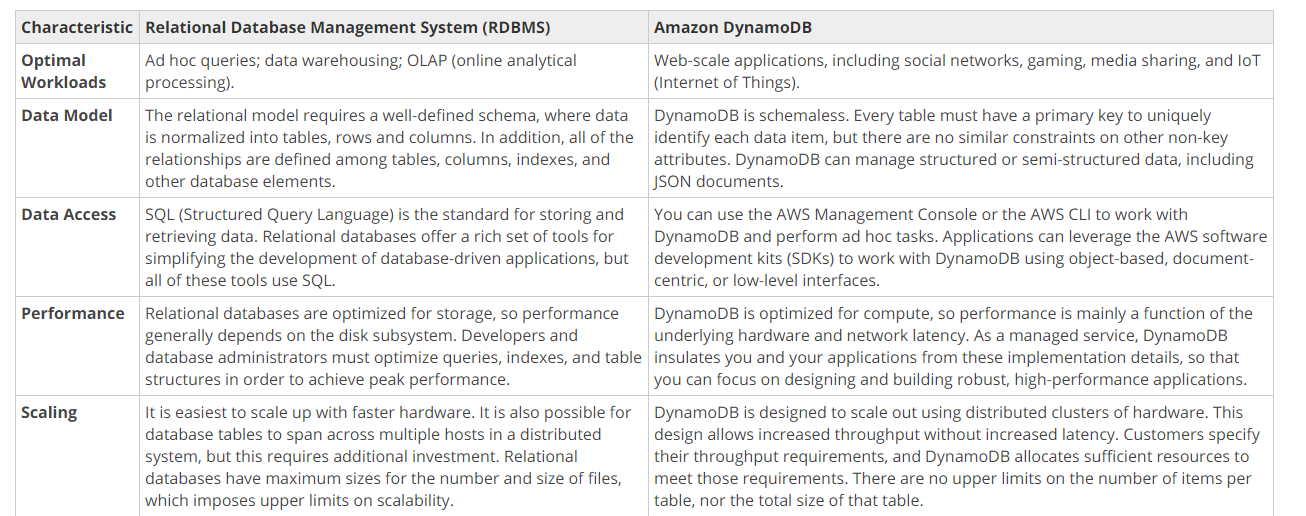
The ideal data store to choose for an application that requires indexing on data without any fixed schema would be AWS DynamoDB, which is a NoSQL database service provided by AWS.
DynamoDB is designed to handle massive amounts of data and provides fast and predictable performance with seamless scalability. It is a fully managed service, which means that AWS takes care of the underlying infrastructure, backups, and software updates.
DynamoDB is a NoSQL database, which means that it doesn't require a fixed schema, and you can store data in a flexible way. This is ideal when you have data that doesn't fit into a fixed schema, as it allows you to add new attributes to your data without having to modify your existing schema.
Furthermore, DynamoDB provides indexing capabilities, which allow you to quickly and efficiently retrieve data based on specific criteria. You can create indexes on one or more attributes, which can be used to filter and sort your data.
In contrast, AWS RDS is a managed relational database service, which requires a fixed schema and is ideal for applications that require a structured data model. AWS Redshift is a data warehousing service, which is optimized for running complex queries and analytics on structured data. AWS S3, on the other hand, is an object storage service that is designed for storing and retrieving unstructured data such as files and multimedia content, and does not provide indexing capabilities.
Therefore, based on the requirements of the application in question, AWS DynamoDB would be the ideal data store to choose.