Reducing Latency for Amazon EC2 Instances in an Auto Scaling Group and Amazon SQS Queue
Question
A SysOps Administrator manages an application where Amazon EC2 instances in an Auto Scaling group read messages from an Amazon SQS queue.
When the message traffic increases, the EC2 instances fall behind, taking too long to process the messages. How can the administrator configure the application to reduce the latency during traffic spikes?
Answers
Explanations
Click on the arrows to vote for the correct answer
A. B. C. D.Correct Answer: B.
This example is also given in the AWS Documentation.
Since the number of messages is the main component for scaling, that should be used in this case.
For more information on scaling based on SQS, please visit the below URL-
https://docs.aws.amazon.com/autoscaling/ec2/userguide/as-using-sqs-queue.html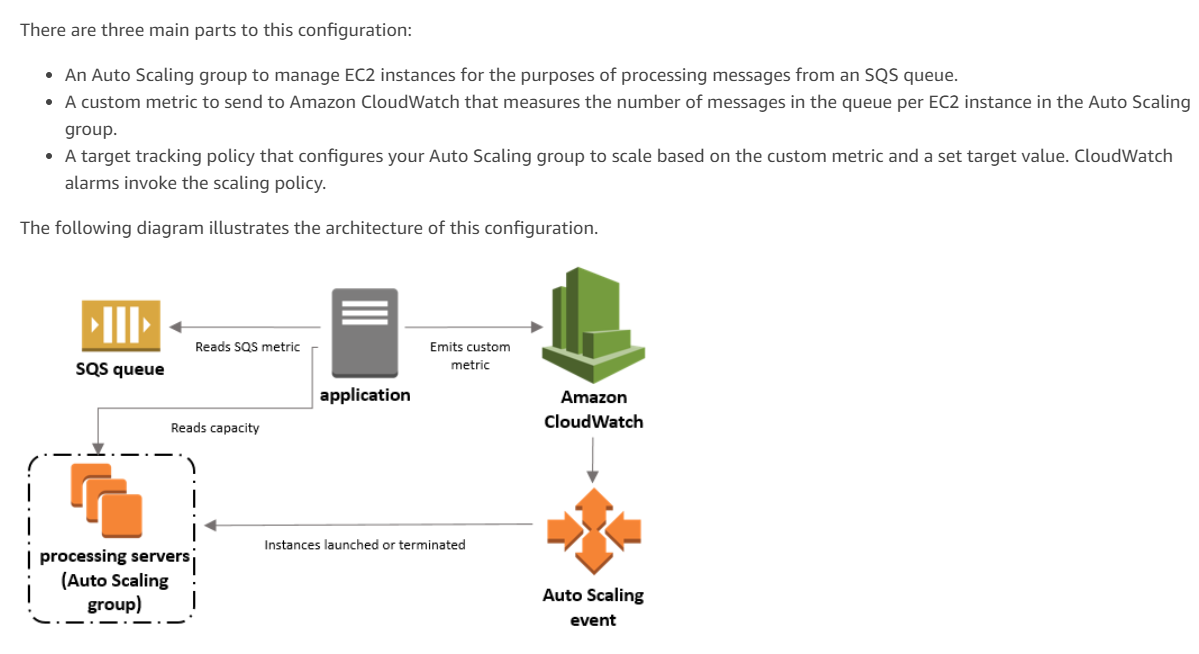
The correct answer to the question is B. Trigger scaling events based on the number of messages in the queue.
Explanation:
Amazon EC2 Auto Scaling allows you to automatically scale your EC2 instances based on demand. By configuring an Auto Scaling group, you can set up a set of EC2 instances that can be automatically scaled based on a set of rules or policies. When demand increases, new instances are added to the group, and when demand decreases, instances are terminated.
Amazon Simple Queue Service (SQS) is a fully managed message queuing service that enables you to decouple and scale microservices, distributed systems, and serverless applications. In this case, the EC2 instances read messages from the SQS queue. When the message traffic increases, the EC2 instances fall behind, taking too long to process the messages.
To reduce the latency during traffic spikes, the SysOps Administrator should configure the application to trigger scaling events based on the number of messages in the queue. This can be done by using CloudWatch Alarms to monitor the number of messages in the queue and trigger an Auto Scaling policy to add new instances to the Auto Scaling group.
This approach ensures that new instances are added to the group only when there is an increase in demand, and instances are terminated when the demand decreases, thus optimizing costs. This approach also ensures that the application can handle increased traffic and reduce latency during traffic spikes.
Option A, Configure the Auto Scaling group to scale based on a schedule, is not the best solution in this case, as it does not take into account the message traffic in the SQS queue.
Option C, Trigger scaling events based on the disk space used on the EC2 instances, is not a good solution, as disk space usage may not always be related to message traffic.
Option D, Manually increment the Auto Scaling group's desired capacity during traffic spikes, is not an optimal solution, as it requires manual intervention and may not be scalable during high traffic spikes.