Choose HDInsight Cluster for Enhanced Data Warehousing and Quick SQL Query Responses
Question
You are a data engineer implementing a lambda architecture on Microsoft Azure. You use an open-source big data solution to collect, process, and maintain data.
The analytical data store performs poorly.
You must implement a solution that meets the following requirements:
-> Provide data warehousing
-> Reduce ongoing management activities
-> Deliver SQL query responses in less than one second
You need to create an HDInsight cluster to meet the requirements.
Which type of cluster should you create?
Answers
Explanations
Click on the arrows to vote for the correct answer
A. B. C. D.D
Lambda Architecture with Azure:
Azure offers you a combination of following technologies to accelerate real-time big data analytics:
1. Azure Cosmos DB, a globally distributed and multi-model database service.
2. Apache Spark for Azure HDInsight, a processing framework that runs large-scale data analytics applications.
3. Azure Cosmos DB change feed, which streams new data to the batch layer for HDInsight to process.
4. The Spark to Azure Cosmos DB Connector
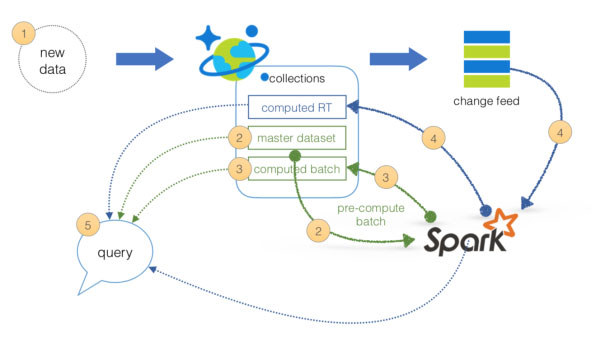
Note: Lambda architecture is a data-processing architecture designed to handle massive quantities of data by taking advantage of both batch processing and stream processing methods, and minimizing the latency involved in querying big data.
https://sqlwithmanoj.com/2018/02/16/what-is-lambda-architecture-and-what-azure-offers-with-its-new-cosmos-db/To meet the given requirements, we need to create an HDInsight cluster that provides data warehousing, reduces ongoing management activities and delivers SQL query responses in less than one second. Out of the four options provided, the most suitable one is an Interactive Query cluster.
An Interactive Query cluster is a type of HDInsight cluster optimized for interactive data querying. It uses the Apache Hive component of Hadoop to provide fast SQL query responses over large volumes of data. It is designed for ad-hoc queries and interactive analysis, which makes it suitable for data warehousing.
Interactive Query clusters are fully managed by Azure, which means that ongoing management activities are reduced. Azure manages the hardware, software updates, and security patches for the cluster, allowing data engineers to focus on data analysis instead of cluster maintenance.
Moreover, Interactive Query clusters can deliver SQL query responses in less than one second, which is a critical requirement for this scenario.
In contrast, Apache Hadoop is a general-purpose, distributed computing system used for processing large volumes of data. It is not optimized for ad-hoc queries and interactive analysis, which makes it less suitable for data warehousing.
Apache HBase is a NoSQL database that provides real-time access to large datasets. It is optimized for random read/write access patterns and is not suitable for ad-hoc queries.
Apache Spark is a fast and general-purpose cluster computing system used for large-scale data processing. While it can provide fast SQL query responses, it is not optimized for ad-hoc queries and interactive analysis, which makes it less suitable for data warehousing.
Therefore, the correct answer is A. Interactive Query.