Migrate On-Premise Database to AWS DynamoDB
Question
A data analysis engineer has an old on-premise database for his meteorology analysis for years.
This database is growing too big and becoming less responsive.
He prefers to migrate it to AWS DynamoDB, and he already has the mapping rules in place.
However, he has been told that the database type is unsupported by AWS Database Migration Service.
He can export the data to CSV format files from the old database.
How can the data analysis engineer migrate the data to AWS DynamoDB successfully?
Answers
Explanations
Click on the arrows to vote for the correct answer
A. B. C. D.Correct Answer - C.
In most cases, when someone is migrating to a new database, he has access to the source database and can use the database directly as a source.
Sometimes, however, he might not have access to the source directly.
In other cases, the source is really old or possibly unsupported.
In these cases, if he can export the data in CSV format, he can still migrate or platform, the data.
In this question, DMS does not support this database type.
However, the CSV files can be used after being uploaded to S3
AWS Database Migration Services (AWS DMS) added support for using Amazon S3 as a source for database migration.
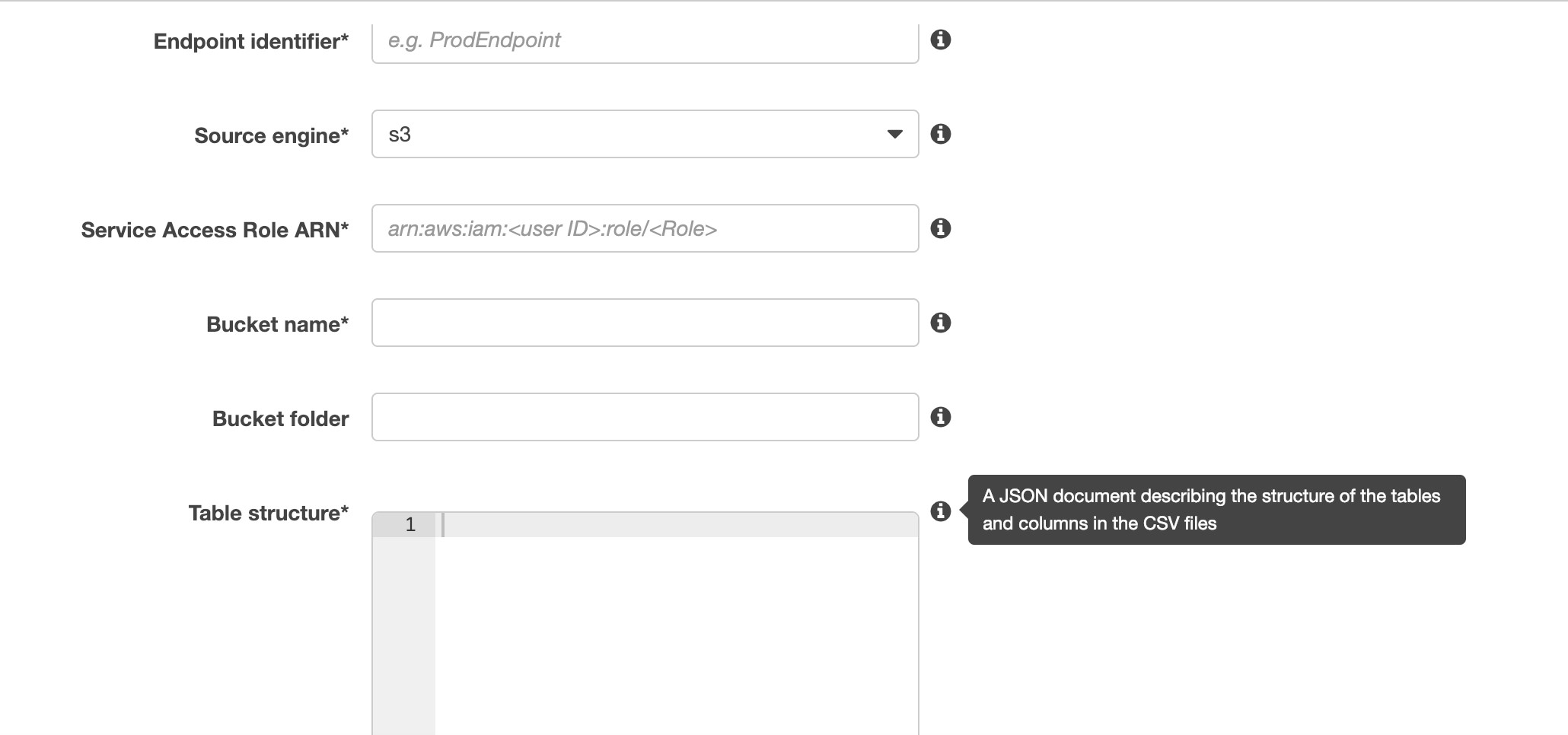
If S3 is the source endpoint, an external table definition is required.
An external table definition is a JSON document that describes how AWS DMS should interpret the data from Amazon S3
The maximum size of this document is 2 MB.
If a source endpoint is created using the AWS DMS Management Console, a JSON file can be entered directly into the table mapping box such as:
Option A is incorrect: Because the mapping rule should be put in the source endpoint configuration rather than the task settings if S3 is the source for DMS.
Option B is incorrect: Because AWS Database Migration Service is suitable.
Moreover, Data Pipeline does not deal with the table mappings.
Data Pipeline is suitable for data backup instead of database migration.
Option C is CORRECT: It correctly describes how to use S3 as the source endpoint and defines the mapping rules.
Below is a piece of JSON mapping rule:
A reference is in https://aws.amazon.com/blogs/database/migrate-delimited-files-from-amazon-s3-to-an-amazon-dynamodb-nosql-table-using-aws-database-migration-service-and-aws-cloudformation/.
Option D is incorrect: Because DynamoDB cannot resolve the table mapping by uploading CSV files exported from databases.
Data Migration Service can deal with this scenario properly.
The correct answer is A. Firstly, upload the CSV files to S3. Create an S3 source endpoint and DynamoDB target endpoint in AWS DMS. Create a migration task by referring to the source and target endpoints. Add the mapping rule in the task using a JSON format.
Explanation:
The given scenario describes a use case where an on-premise database needs to be migrated to AWS DynamoDB. The database type is unsupported by AWS Database Migration Service, and the data analysis engineer has to export the data to CSV format files from the old database.
To migrate the data to AWS DynamoDB successfully, the following steps can be performed:
Upload CSV files to S3: The first step is to upload the CSV files to an S3 bucket. This can be done by creating a bucket in the AWS Management Console and using the Upload feature to upload the CSV files.
Create S3 source endpoint and DynamoDB target endpoint: In the AWS DMS console, create a source endpoint using the S3 bucket as the source. Then, create a target endpoint using DynamoDB as the target.
Create a migration task: Create a migration task in AWS DMS by referring to the source and target endpoints. This task will be responsible for moving the data from the source endpoint to the target endpoint.
Add mapping rule using JSON format: In the migration task, add a mapping rule to map the data from the CSV files to the DynamoDB table using a JSON format. This mapping rule will ensure that the data is correctly transformed and loaded into the DynamoDB table.
By following the above steps, the data analysis engineer can successfully migrate the data from the on-premise database to AWS DynamoDB.
Option B is incorrect because while AWS Data Pipeline can be used to import data from S3 to DynamoDB, it is not the most appropriate solution for this scenario.
Option C is incorrect because while it mentions using AWS DMS, it incorrectly suggests adding a table mapping rule with a JSON table structure instead of a JSON format.
Option D is incorrect because while it correctly mentions that DynamoDB supports the import of CSV files directly, it does not mention the need to upload the files to S3 first. Additionally, it does not provide the steps for creating a proper schema for the DynamoDB table.
