AWS Data Pipeline for Sentiment Analysis
Question
You work for a startup e-commerce site that sells various consumer products.
Your company has just launched its e-commerce website.
The site provides the capability for your users to rate their purchases and the products they have purchased from your e-commerce site.
You would like to use the review data to build a recommender machine learning model. Since your e-commerce site is very new, you don't yet have a very large review dataset to use for your recommendation model.
You have decided to use the Amazon Customer Reviews dataset from the AWS website as a first data source for your machine learning model.
Since your website sells similar products to the products sold on Amazon, you will use the Amazon Customer Reviews dataset as the basis for your initial training runs of your model.
Once you have enough data from your own e-commerce site, you'll use that data. Your goal is to perform sentiment analysis on the review dataset to create your own dataset that will be the source used for your recommender machine learning model.
Which set of AWS services would you use to build your data pipeline to produce your sentiment dataset for use by your SageMaker model?
Answers
Explanations
Click on the arrows to vote for the correct answer
A. B. C. D.Answer: A.
Option A is correct.
The Amazon Customer Reviews dataset is stored on S3
You can use an AWS Glue ETL job to read the reviews from the Amazon dataset.
The ETL job calls Comprehend for each review to get the sentiment for that review.
The ETL job stores the sentiment enriched review data onto another S3 bucket in your account.
Your SageMaker model uses the S3 bucket in your account as its dataset source for training your recommender model.
Option B is incorrect.
This option has unnecessary steps.
Specifically, you don't need Athena and QuickSite to produce your sentiment enriched dataset for your machine learning model.
Option C is incorrect.
The option uses Kinesis Data Firehose unnecessarily.
The Amazon Customer Reviews dataset is stored on S3
There is no need to stream the data when you can simply read it using an ETL job.
If you used Kinesis Data Firehose to stream the data, you would have to write a lambda function to call Comprehend for each streamed review data row.
Option D is incorrect.
The option uses Kinesis Data Firehose unnecessarily.
The Amazon Customer Reviews dataset is stored on S3
There is no need to stream the data when you can simply read it using an ETL job.
That being said, this option does correctly combine Kinesis Data Firehose and lambda.
However, it lacks the Comprehend service.
You would have to write your own sentiment analysis in your lambda function.
Reference:
Please see the data repository titled Registry of Open Data on AWS, the AWS Machine Learning blog titled How to scale sentiment analysis using Amazon Comprehend, AWS Glue and Amazon Athena, and the data set titled Amazon Customer Reviews Dataset.
Here is a diagram of the proposed solution:
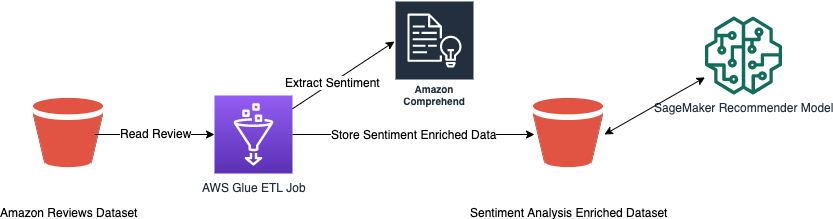
For building a data pipeline to produce a sentiment dataset for use by a SageMaker model, we need to follow a few steps:
Collect data: Since the company is new and does not have a lot of review data, we will use the Amazon Customer Reviews dataset from the AWS website.
Store data: We will store the Amazon Customer Reviews dataset in an S3 bucket.
Transform data: We will use AWS Glue ETL to transform the Amazon Customer Reviews dataset.
Perform sentiment analysis: We will use Amazon Comprehend to perform sentiment analysis on the transformed dataset.
Store the sentiment dataset: We will store the sentiment dataset in an S3 bucket.
Train the model: We will use SageMaker to train the recommender machine learning model.
Based on the above steps, the correct answer is A. S3 -> AWS Glue ETL -> Comprehend -> S3 -> SageMaker.
Explanation of each step:
Step 1: Collect data Since the e-commerce site is new and does not have enough review data, we will use the Amazon Customer Reviews dataset from the AWS website. The dataset contains customer reviews and ratings for various products sold on Amazon.
Step 2: Store data We will store the Amazon Customer Reviews dataset in an S3 bucket. This dataset will serve as the basis for our initial training runs of the model.
Step 3: Transform data We will use AWS Glue ETL to transform the Amazon Customer Reviews dataset. AWS Glue is a fully managed extract, transform, and load (ETL) service that makes it easy to move data between data stores. We will use AWS Glue to transform the dataset into a format that can be used by Comprehend for sentiment analysis.
Step 4: Perform sentiment analysis We will use Amazon Comprehend to perform sentiment analysis on the transformed dataset. Amazon Comprehend is a natural language processing (NLP) service that uses machine learning to find insights and relationships in text. We will use Comprehend to determine the sentiment of each review in the dataset.
Step 5: Store the sentiment dataset We will store the sentiment dataset, which includes the sentiment of each review in the Amazon Customer Reviews dataset, in an S3 bucket. This dataset will serve as the source used for our recommender machine learning model.
Step 6: Train the model We will use SageMaker to train the recommender machine learning model. SageMaker is a fully managed service that provides developers and data scientists with the ability to build, train, and deploy machine learning models quickly and easily. We will use the sentiment dataset created in the previous steps as the training data for our model.
