Question 60 of 170 from exam DP-200: Implementing an Azure Data Solution
Question
DRAG DROP -
Your company manages on-premises Microsoft SQL Server pipelines by using a custom solution.
The data engineering team must implement a process to pull data from SQL Server and migrate it to Azure Blob storage. The process must orchestrate and manage the data lifecycle.
You need to configure Azure Data Factory to connect to the on-premises SQL Server database.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
Select and Place:
Explanations
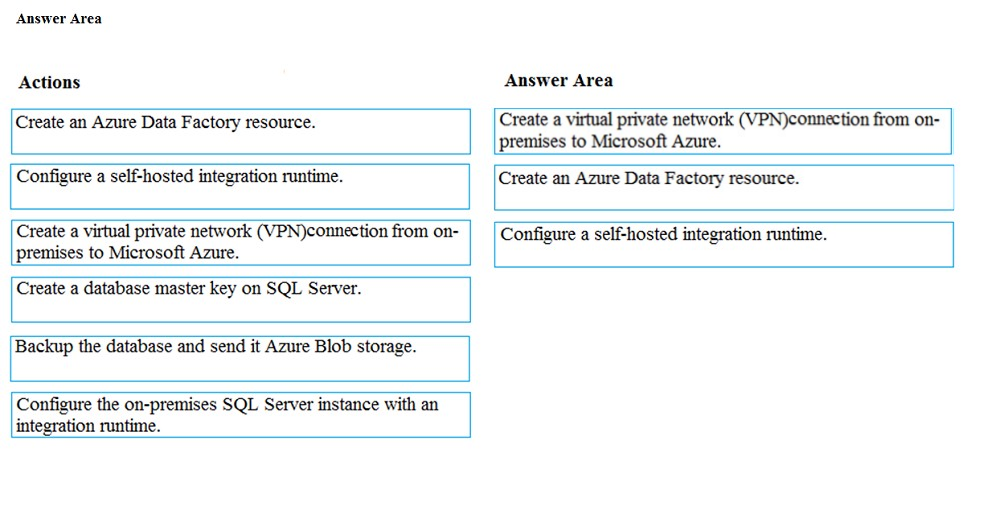
Step 1: Create a virtual private network (VPN) connection from on-premises to Microsoft Azure.
You can also use IPSec VPN or Azure ExpressRoute to further secure the communication channel between your on-premises network and Azure.
Azure Virtual Network is a logical representation of your network in the cloud. You can connect an on-premises network to your virtual network by setting up IPSec
VPN (site-to-site) or ExpressRoute (private peering).
Step 2: Create an Azure Data Factory resource.
Step 3: Configure a self-hosted integration runtime.
You create a self-hosted integration runtime and associate it with an on-premises machine with the SQL Server database. The self-hosted integration runtime is the component that copies data from the SQL Server database on your machine to Azure Blob storage.
Note: A self-hosted integration runtime can run copy activities between a cloud data store and a data store in a private network, and it can dispatch transform activities against compute resources in an on-premises network or an Azure virtual network. The installation of a self-hosted integration runtime needs on an on- premises machine or a virtual machine (VM) inside a private network.
https://docs.microsoft.com/en-us/azure/data-factory/tutorial-hybrid-copy-powershell