Question 88 of 170 from exam DP-200: Implementing an Azure Data Solution
Question
HOTSPOT -
You develop data engineering solutions for a company.
A project requires an in-memory batch data processing solution.
You need to provision an HDInsight cluster for batch processing of data on Microsoft Azure.
How should you complete the PowerShell segment? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
Explanations
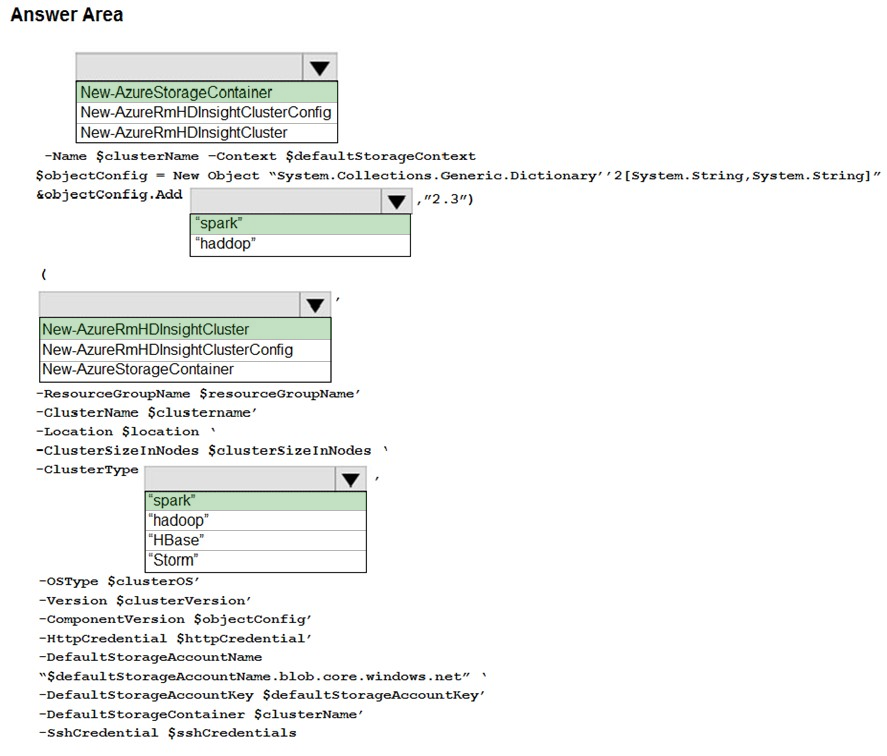
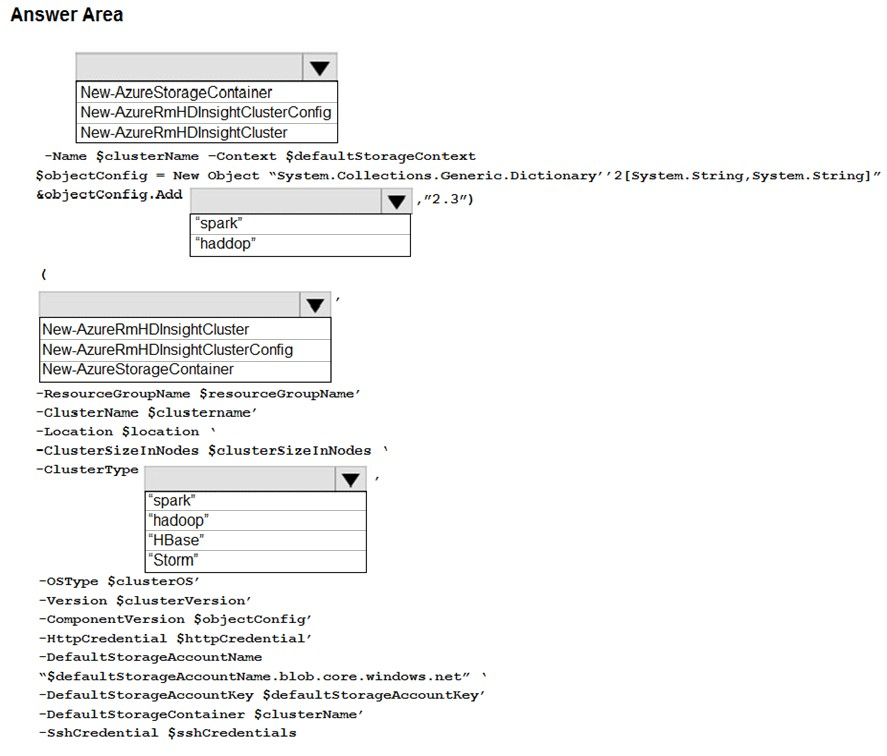
Box 1: New-AzStorageContainer -
# Example: Create a blob container. This holds the default data store for the cluster.
New-AzStorageContainer '
-Name $clusterName '
-Context $defaultStorageContext
$sparkConfig = New-Object "System.Collections.Generic.Dictionary''2[System.String,System.String]"
$sparkConfig.Add("spark", "2.3")
Box 2: Spark -
Spark provides primitives for in-memory cluster computing. A Spark job can load and cache data into memory and query it repeatedly. In-memory computing is much faster than disk-based applications than disk-based applications, such as Hadoop, which shares data through Hadoop distributed file system (HDFS).
Box 3: New-AzureRMHDInsightCluster
# Create the HDInsight cluster. Example:
New-AzHDInsightCluster '
-ResourceGroupName $resourceGroupName '
-ClusterName $clusterName '
-Location $location '
-ClusterSizeInNodes $clusterSizeInNodes '
-ClusterType $"Spark" '
-OSType "Linux" '
Box 4: Spark -
HDInsight is a managed Hadoop service. Use it deploy and manage Hadoop clusters in Azure. For batch processing, you can use Spark, Hive, Hive LLAP,
MapReduce.
https://docs.microsoft.com/bs-latn-ba/azure/hdinsight/spark/apache-spark-jupyter-spark-sql-use-powershell https://docs.microsoft.com/bs-latn-ba/azure/hdinsight/spark/apache-spark-overview